Benchmarks
Benchmarks for LiteLLM Gateway (Proxy Server) tested against a fake OpenAI endpoint.
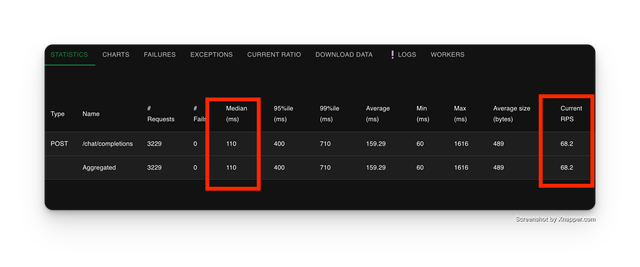
1 Instance LiteLLM Proxy
| Metric | Litellm Proxy (1 Instance) |
|---|
| Median Latency (ms) | 110 |
| RPS | 68.2 |
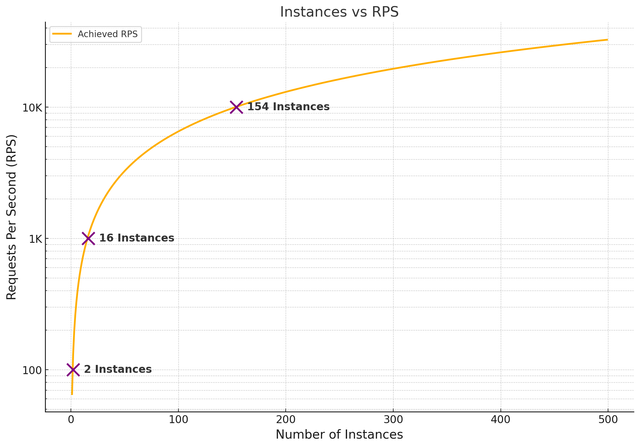
Horizontal Scaling - 10K RPS
Key Findings
- Single instance: 68.2 RPS @ 100ms latency
- 10 instances: 4.3% efficiency loss (653 RPS vs expected 682 RPS), latency stable at
100ms - For 10,000 RPS: Need ~154 instances @ 95.7% efficiency,
100ms latency
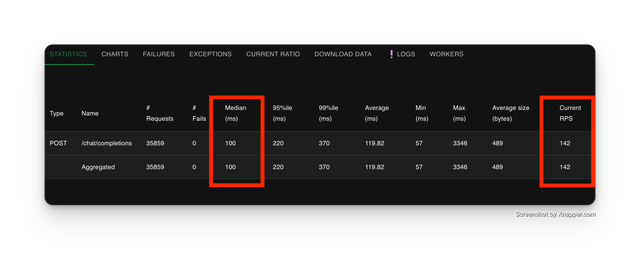
2 Instances
Adding 1 instance, will double the RPS and maintain the 100ms-110ms median latency.
| Metric | Litellm Proxy (2 Instances) |
|---|
| Median Latency (ms) | 100 |
| RPS | 142 |
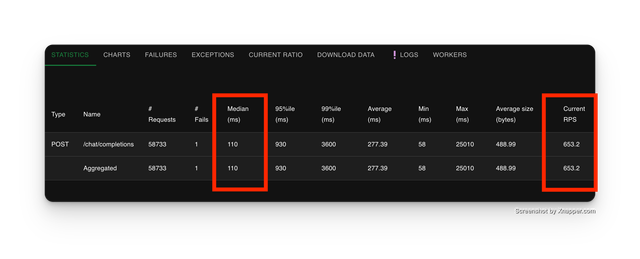
10 Instances
| Metric | Litellm Proxy (10 Instances) |
|---|
| Median Latency (ms) | 110 |
| RPS | 653 |
Logging Callbacks
Using GCS Bucket has no impact on latency, RPS compared to Basic Litellm Proxy
| Metric | Basic Litellm Proxy | LiteLLM Proxy with GCS Bucket Logging |
|---|
| RPS | 1133.2 | 1137.3 |
| Median Latency (ms) | 140 | 138 |
Using LangSmith has no impact on latency, RPS compared to Basic Litellm Proxy
| Metric | Basic Litellm Proxy | LiteLLM Proxy with LangSmith |
|---|
| RPS | 1133.2 | 1135 |
| Median Latency (ms) | 140 | 132 |
Locust Settings
- 2500 Users
- 100 user Ramp Up